Feed Aggregator Page 678
Rendered on Mon, 31 Jan 2022 13:02:33 GMT
|
|
Lisplog |
Rendered on Mon, 31 Jan 2022 13:02:33 GMT
via Elm - Latest posts by @r4z4 on Thu, 27 Jan 2022 01:05:12 GMT

via Elm - Latest posts by @Sebastian Sebastian on Wed, 26 Jan 2022 22:52:45 GMT
It is trying to discourage the use of the nested Elm architecture pattern Nested TEA - Elm Patterns. Commonly Html.map is used in this pattern. This pattern is useful but is best to leave it for when it is really needed. It brings a good amount of complexity and boilerplate, so it better to find alternative solutions first.
If Html.map is useful for you without the whole Nested TEA pattern then there is not reason not to use it.
via Planet Lisp by on Wed, 26 Jan 2022 18:33:11 GMT
#CommonLisp #Lisp #Tip
Sometimes you need to do something only if control in your code zips by so fast that you cannot grab it... and you do not really care if goes by slowly. Like, you know, when you are suspicious that it would be doing something funky rather than going by and doing its business.
In other words, sometimes you are in need of detecting non-local exits from a block of code while ignoring normal returns.
There's an idiom for that - using LET over UNWIND-PROTECT.
;;; © Michał "THEN PAY WITH YOUR BLOOD" Herda 2022
(defun oblivion (thunk)
(let ((successfulp nil))
(unwind-protect (multiple-value-prog1 (funcall thunk)
(setf successfulp t))
(unless successfulp
(error "STOP RIGHT THERE CRIMINAL SCUM")))))
CL-USER> (oblivion (lambda () (+ 2 2)))
4
CL-USER> (block nil (oblivion (lambda () (return-from nil 42))))
;;; Error: STOP RIGHT THERE CRIMINAL SCUM
;;; [Condition of type SIMPLE-ERROR]
The explanation is simple: we bind a variable with a default value which assumes that there was a non-local exit.
Then we execute our block of code in an UNWIND-PROTECT, and only after it executes successfully we set that value again to denote that running our code succeeded and we are ready to return its values.
The cleanup forms of the UNWIND-PROTECT are conditionalized on the same variable and will only trigger if the SETF SUCCESSFULP T did not execute - and that only happens if there was a non-local exit that prevented it from occurring.
In fact, there's an Alexandria utility that does just that! The macro ALEXANDRIA:UNWIND-PROTECT-CASE is capable of supporting this behavior.
;;; (ql:quickload :alexandria)
(catch 'foo
(alexandria:unwind-protect-case ()
(throw 'foo 1)
(:abort (format t "ABORTED"))))
Thanks to Stelian Ionescu for the heads-up!
via Planet Lisp by on Fri, 21 Jan 2022 21:44:00 GMT
Hi
as many may know, I have been nursing (almost to death!) the Common Lisp Document Repository (CDR). Pascal Costanza et al., started the project many years ago and then I sat on top of it for many more.
I finally found some time to work on it and the result is a revamped site (cdr.common-lisp.dev) with the addition of stashing documents in a Zenodo Community (CDR), which has the benefit of producing a DOI for each write-up.
Moreover, Pascal Bourguignon, Michał "phoe" Herda and Didier Verna have agreed to become CDR editors. Many thanks to them.
So, if anyone wants to submit a "specification" for something of interests to the CL community, she/he is most welcome to do so. Just remember that good specifications are not so easy to write.
(cheers)
via Planet Lisp by on Thu, 20 Jan 2022 20:25:04 GMT
#CommonLisp #Lisp
I wrote a kinda-long post in which:
Because of its length (and because of current Movim technical issues wrt rendering Markdown and Common Lisp), it's on its own separate page. You can read it here.
via Planet Lisp by on Tue, 18 Jan 2022 06:30:46 GMT
Hi, all Common Lispers.
In the previous post, I introduced "Roswell script", the powerful scripting integration of Roswell. Not only does it allow to provide a command-line interface, but it makes it easy to install via Roswell. In this point of view, Roswell can be regarded as a distribution system for Common Lisp applications.
Today's topic is related — the speed of scripts.
Let's begin with the following simple Roswell script. It's a pretty simple one that just prints "Hello" and quits.
#!/bin/sh
#|-*- mode:lisp -*-|#
#|
exec ros -Q -- $0 "$@"
|#
(progn ;;init forms
(ros:ensure-asdf))
(defpackage :ros.script.hello.3850273748
(:use :cl))
(in-package :ros.script.hello.3850273748)
(defun main (&rest argv)
(declare (ignorable argv))
(write-line "Hello"))
;;; vim: set ft=lisp lisp:
$ ./hello.ros
Hello
Though people expect this simple script to end instantly, it takes longer.
$ time ./hello.ros
Hello
real 0m0.432s
user 0m0.315s
sys 0m0.117s
0.4 seconds to print "Hello". It feels like an early scripting language.
An equivalent script with sbcl --script is much faster for the record.
$ time ./hello.lisp
Hello
real 0m0.006s
user 0m0.006s
sys 0m0.000s
Fortunately, there're several solutions to this problem.
I have to admit that the Roswell script can't be faster than sbcl --script since it does many things, but it's possible to make it closer.
The first bottleneck is "Quicklisp".
Quicklisp is a de fact standard and available anywhere today, so we may not realize the cost of loading it. But, it can't be ignored in scripting.
Fortunately, it's easy to disable Quicklisp in the Roswell script. Just replace -Q with +Q in the exec line.
#!/bin/sh
#|-*- mode:lisp -*-|#
#|
-exec ros -Q -- $0 "$@"
+exec ros +Q -- $0 "$@"
|#
(progn ;;init forms
(ros:ensure-asdf))
Let's see the difference.
# No Quicklisp version
$ time ./hello.ros
Hello
real 0m0.142s
user 0m0.119s
sys 0m0.020s
It's approximately 0.3 seconds faster. Conversely, it takes this long to load Quicklisp. This is not little time for a program that starts many times, like scripts.
Additionally, omit ros:ensure-asdf since ASDF is unnecessary in this script.
exec ros +Q -- $0 "$@"
|#
(progn ;;init forms
- (ros:ensure-asdf))
+ )
(defpackage :ros.script.hello.3850273748
(:use :cl))
$ time ./hello.ros
Hello
real 0m0.072s
user 0m0.052s
sys 0m0.020s
ASDF seems to require to load approximately 0.07 sec. Now, it's 6 times faster.
These changes are effective for small scripts which don't require Quicklisp or ASDF.
Even in the case of scripts that use Quicklisp and ASDF, this method can be applied partially by loading them conditionally.
For example, a script has several subcommands like run or help.
Let's suppose run requires Quicklisp to load the main application, and help doesn't.
If you use -Q option, Quicklisp will make help command slow though it doesn't require Quicklisp.
In this case, it is better to use the +Q option and load Quicklisp if necessary.
ros:quicklisp is a function to load Quicklisp manually, even when the ros started with +Q. By calling this function right before Quicklisp is needed, it's possible to make the other part faster.
What about in case of fairly complicated applications which must require Quicklisp to load external dependencies.
Building a binary is a prevailing solution.
I suppose it won't surprise you. It's a common technique even in no Roswell world. Also, I've mentioned ros build in the previous article, which makes a binary executable from a Roswell script.
However, we can't assume people always run ros build to speed up your application after installation.
Roswell takes care of it. Roswell has a feature to build the script dump implicitly to speed up its execution.
Add -m' option to theexec ros` line. Then, enable Quicklisp and ASDF to see how this feature is practical.
@@ -1,10 +1,10 @@
#!/bin/sh
#|-*- mode:lisp -*-|#
#|
-exec ros +Q -- $0 "$@"
+exec ros -Q -m hello -- $0 "$@"
|#
(progn ;;init forms
- )
+ (ros:ensure-asdf))
(defpackage :ros.script.hello.3850273748
(:use :cl))
And install the script.
$ ros install hello.ros
/home/fukamachi/.roswell/bin/hello
Let's try it. It'll take a little time for Roswell to dump a core named hello.core for the first time.
$ hello
Making core for Roswell...
building dump:/home/fukamachi/.roswell/impls/arm64/linux/sbcl-bin/2.2.0/dump/hello.core
WARNING: :SB-EVAL is no longer present in *FEATURES*
Hello
The second time, it's way faster.
$ time hello
Hello
real 0m0.032s
user 0m0.009s
sys 0m0.024s
It's approximately 13 times faster than the initial version. Of course, it includes the load time of Quicklisp and ASDF.
Remember that this requires the script to be installed at ~/.roswell/bin via ros install.
A living example is "lem", a text editor written in Common Lisp.
In the case of "lem", it requires lots of dependencies to run, and people expect a text editor to launch instantly. The dumping core works nicely for it.
# Installation
$ ros install lem-project/lem
# Takes a little time for the first time
$ lem
Making core for Roswell...
building dump:/home/fukamachi/.roswell/impls/arm64/linux/sbcl-bin/2.2.0/dump/lem-ncurses.core
WARNING: :SB-EVAL is no longer present in *FEATURES*
# === lem is opened in fullscreen ===
# Type C-x C-c to quit
It takes a little time to boot up the first time, but the second time is quicker. Also, it'll be dumped again when Roswell detects some file changes.
Note that the name of the core needs to be unique. If there is a conflict, Roswell will load a different core.
Actually, this behavior doesn't go with Qlot well. If there's an application installed in user local and another installed in project local, Roswell can't distinguish between their cores. So then, even if you think you have fixed the version of the library, it will be using a core with a different version loaded.
This is not a problem for independent software like lem, but you should be careful with applications that load other software while running. A bad example of this problem is "Lake".
In this article, I introduced a technique to speed up the startup of Roswell scripts.
+Q to disable loading QuicklispF-m optionBoth have pros and cons.
The nice thing about the `-m' option is that the end-user doesn't need to be aware of it, which is a good part of Roswell as a distribution system for Common Lisp applications.
via Planet Lisp by on Mon, 17 Jan 2022 20:22:46 GMT
#CommonLisp #Lisp
> Let us say, for the sake of simplicity, a fence or gate erected across a road. The more modern type of reformer goes gaily up to it and says, 'I don't see the use of this; let us clear it away.' To which the more intelligent type of reformer will do well to answer: 'If you don't see the use of it, I certainly won't let you clear it away. Go away and think. Then, when you can come back and tell me that you do see the use of it, I may allow you to destroy it.' > > -- Wikipedia - Chesterton's fence
UIOP:DEFINE-PACKAGE is the part of UIOP that I personally use the most - it fills (IMO) the biggest hole in the Common Lisp package system, which is CLHS Macro DEFPACKAGE saying:
> If the new definition is at variance with the current state of that package, the consequences are undefined; (...)
This means that removing an export from a DEFPACKAGE can cause your implementation to wag a finger at you, and also ignore your attempt at removing it.
CL-USER> (defpackage #:foo (:use) (:export #:bar))
#<PACKAGE "FOO">
CL-USER> (defpackage #:foo (:use) (:export))
;; WARNING: FOO also exports the following symbols:
;; (FOO:BAR)
;; See also:
;; The ANSI Standard, Macro DEFPACKAGE
;; The SBCL Manual, Variable *ON-PACKAGE-VARIANCE*
#<PACKAGE "FOO">
CL-USER> (loop for sym being the external-symbols of :foo
collect sym)
(FOO:BAR)
The solution is to manually call UNEXPORT on FOO::BAR, at which point SBCL will calm down and let you evaluate the second DEFPACKAGE form in peace.
DEFINE-PACKAGE, in the same situation, will do "the right thing" (read: the thing I personally expect it to) and adjust the package's export list to be consistent with the one provided to it.
CL-USER> (uiop:define-package #:foo (:use) (:export #:bar))
#<PACKAGE "FOO">
CL-USER> (uiop:define-package #:foo (:use) (:export))
#<PACKAGE "FOO">
CL-USER> (loop for sym being the external-symbols of :foo
collect sym)
NIL
There's plenty of other useful options, such as :MIX, :REEXPORT and all, but there's one of them that looks... A bit off.
The option :UNINTERN is specified to call CL:UNINTERN on some symbols when the package is defined.
Hold up, wait a second, though. Uninterning symbols? During package definition?
When a package is defined for the first time, there are no symbols to unintern. This means that this option is only useful when a package already exists, and therefore UIOP:DEFINE-PACKAGE is used to redefine it.
This, and uninterning cannot be used to achieve "partial :use", that is, to remove symbols from packages that are :used in the current package in order to only "use a part of" this other package. That simply isn't doable in Common Lisp - :use imports all of the symbols exported by another package, except those that are explicitly :shadowed.
So, again, what's the point? Scroll down only if you'd like the mystery to be spoiled to you.
Let's assume a very simple situation:
(defpackage #:bar
(:use)
(:export #:symbol))
We have a single package which exports a single symbol. That package was created by some software which we use, and the symbol BAR:SYMBOL is useful to us in some way.
And then, while our Lisp image is still running, we'd like to upgrade this software to a new version. That is, we'd like to load a new version of that software and disregard the old one. In the new version of our software, the package structure looks like this:
(defpackage #:foo
(:use)
(:export #:symbol))
(defpackage #:bar
(:use #:foo)
(:export #:symbol))
It seems that the symbol named SYMBOL was moved into another package, possibly because that is where the implementation of that symbol has been moved to. Oh well, looks understandable from a software architecture point of view!
...and then trying to load the upgraded version will fail at the very beginning. Worse - it might fail, since we have just stepped into undefined behavior area, as stated in the beginning of this post.
In particular, DEFPACKAGE FOO will be evaluated without any problem, but a keen eye will notice an error which will be signaled the moment we evaluate DEFPACKAGE BAR. The currently existing package contains its own version of the symbol named SYMBOL, whereas the new requirement is to :USE the package FOO, which has its own symbol named SYMBOL - a classic package name conflict.
What is the producer of this piece of software to do now in order to ensure a smooth transition?
One way forward is to DELETE-PACKAGE before moving on with the upgrade, but that's pretty explosive - if BAR exported any other symbols, naming e.g. class definitions, then this means trouble for us. Another way forward is to manually call UNINTERN before calling DEFPACKAGE, but only if the package already exists - and that is a little bit messy.
And this is exactly the problem that is meant to be solved by UIOP:DEFINE-PACKAGE. In particular, this utility is capable of automatically changing the structure of the underlying package to resolve conflicts in favor of the newly added symbols. We can simply use it as a drop-in replacement for DEFPACKAGE, like this:
(defpackage #:foo
(:use)
(:export #:symbol))
(uiop:define-package #:bar
(:use #:foo)
(:export #:symbol))
That change allows this code to compile and load without errors. In particular, we can verify that BAR:SYMBOL correctly resolves to the new symbol from package FOO:
CL-USER> 'bar:symbol
FOO:SYMBOL
So, that's one upgrading problem less, solved by using UIOP:DEFINE-PACKAGE instead of DEFPACKAGE.
...but, uh, what about DEFINE-PACKAGE :UNINTERN? That's still not the end of the story.
Let us assume that you are the developer of Lisp software who is working on it and you are testing the scenario in which you upgrade one version of software to another. The technique described above works well with regard to upgrading software, but let's say that your package definition looked like this:
(defpackage #:foo
(:use)
(:intern #:some #:totally-random #:stuff))
And you want to replace it with the following:
(uiop:define-package #:foo
(:use)
(:intern #:some #:totally-randomized #:stuff))
The explanation is that TOTALLY-RANDOM was a symbol that was useful (and used) in the previous version of software, but the new version uses something better, which also has a better name - TOTALLY-RANDOMIZED.
And all is fine and well, until you go into your REPL and see this:
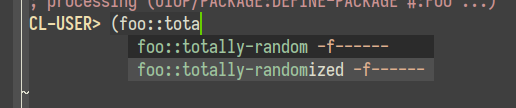
The syntax completion is suggesting the old symbol even though it no longer bears any meaning. It means that you, as the programmer, need to hit the ↓ key to navigate downwards and select the proper symbol, which can annoy you to no avail. That's a pet peeve.
But it also means that you have the possibility of introducing bugs into the system by using the old version of a function - or, worse, breaking the build by using a symbol that is only present on systems upgraded from the old version and not ones which had the new version loaded start from scratch.
That's actually scary.
And that's the concrete edge case solved by :UNINTERN!
(uiop:define-package #:foo
(:use)
(:intern #:totally-randomized)
(:unintern #:totally-random))
Using this fixes the syntax completion:

Evaluating this :UNINTERN option inside DEFINE-PACKAGE will either be a no-op (if the symbol doesn't exist, e.g. when defining the package from scratch) or automatically unintern the old symbol from the system (if it exists, e.g. when upgrading the package to a newer version).
In particular, the second option will happen even if the current shape of the source code no longer has any other mentions of it and even if this :UNINTERN call seems to make no sense.
In this context, :UNINTERN is something protecting the programmer from a danger that may no longer be relevant for current versions of the software, but was once something that the programmer considered important enough to remove during a software upgrade. This :UNINTERN should stay in the source code for however long it is supported to make upgrades from the versions of software which still used this symbol to the current version.
Hell of an edge case, eh? As always, it's an edge case until you hit it and need a tool for solving it - and :UNINTERN fits that description pretty damn well.
And let's not think about the scenario where your software needs to reintroduce that symbol later on, possibly for different purposes... and support all the upgrade paths along the way.
This, and I heard that it's useful when developing, especially with one-package-per-file style (which also includes ASDF's package-inferred systems); I heard that it's more convenient to jump to the top of the file, add a (:UNINTERN #:FOO) clause to the UIOP:DEFINE-PACKAGE there, reevaluate the form, remove the clause, and keep on hacking, rather than change Emacs buffers in order to jump into the REPL and evaluate a (UNINTERN '#:FOO) form there.
Personally, though, I don't share the sentiment - I can use C-↓ or C-↑ anywhere in the file to go out of whatever form my cursor is in, write a (UNINTERN '#:FOO), C-c C-c that form to get Slime to evaluate it, and then delete the form and continue hacking.
UIOP:DEFINE-PACKAGE's :UNINTERN option is useful in the rare and obscure situations when all of the following are true:
This is useful e.g. for avoiding invalid syntax completions inside your Lisp image.
Thanks to Robert Goldman and Phoebe Goldman for helping me solve the mystery of :UNINTERN.
Thanks to Francis St-Amour for his long and painful review of this post.
Thanks to Catie from #lispcafe on Libera Chat and Gnuxie for shorter, less painful reviews of this post.
via Planet Lisp by on Mon, 17 Jan 2022 09:00:00 GMT
In case you haven't seen it, the ASDF maintainer is considering resigning. The reason is pretty straightforward: continued antagonization toward the ASDF team from a prominent CL developer (and maintainer of a number of widely used libraries) and the seeming acceptance of this by the CL community.
The only other forum I'm aware of that's discussing this is this Reddit thread. However, I found most of the conversation in that thread simultaneously depressing and wildly missing the point. So I decided to take advantage of this space to speak my thoughts clearly, plainly, and without interruption or other noise surrounding them.
Side note: if you know of some other place this is being discussed, I'd love to know. Bonus points if it's not a SOS's pool.
Full disclosure: I am an ASDF developer, but I was not a developer when most of the relevant events happened. I am u/daewok on the Reddit thread. Last, I think Robert has done a great job shepherding ASDF and don't want to see him resign, especially over this.
The current flash point is this flexi-streams GitHub issue. However, the tensions have been building for quite a while.
Basically, ASDF 3.mumble improved upon an under-specified area of defining multiple systems per .asd file. The new method improved reliability, improved safety, and reduced user surprise. The cost is that a certain system naming convention needs to be followed. The naming convention is even backward compatible (if you adopt the new convention, it'll still work exactly as expected on older ASDF versions).
But even then, ASDF didn't even break extant naming schemes: all it does is signal a warning telling the user about the updated naming scheme. I personally would love it if, at some point, ASDF stops supporting anything other than the new scheme. But we are years away from considering that (ideally after everyone has adopted the new (and I can't emphasize this enough: backward compatible) naming scheme).
A mixture of ASDF and non-ASDF developers have submitted patches to projects to use the updated naming scheme. The fact that non-ASDF developers have gotten involved shows that the warning works. Most projects have accepted these patches. However, there was a notable holdout in the edicl-verse. Not only did this maintainer refuse to apply the trivial patches, they openly expressed their hope that as many people as possible would complain to the ASDF devs. This latter behavior is what Robert is unspeakably frustrated by and is what prompted his resignation consideration.
Let me get this out of the way first: could Robert's initial interaction on the flexi-streams issue been better? Almost certainly. But I'm willing to cut him a little slack given that his previous interactions in other threads were collegial, I know he's been antagonized a lot over this issue and similar ones throughout the years, and were are (still) in the middle of a pandemic that's affecting everyone in different ways.
I think this antagonization of the volunteer team maintaining a widely used piece of CL infrastructure is something that very much needs to be discussed. Like I said in the intro, the Reddit thread is the only place I've really seen it discussed in any depth. And that's a shame, because the discussion there missed the point in two major ways.
First, there was a group of people that focused on the technical issues at hand. Basically things like: "should ASDF have made this change?", "the warning being signaled is unnecessary in this specific case!", "why is ASDF signaling warnings at all!?" Which, in addition to missing the point of Robert's email entirely, also managed to demonstrate that people have shockingly strong opinions on what they want the world to look like, but have made little to no effort to make it happen in a positive way. I can definitely say that the ASDF team would love it if more people were involved in developing and testing the shared resource that is ASDF!
Second, there was the group that believed that the maintainer had the absolute right to ignore/reject the patches and that ends the discussion. I give this group credit for at least discussing a non-technical aspect of this. And while they are correct that he could ignore the patches, it misses the more interesting questions of should he have rejected the patches and was his behavior in calling for as many complaints as possible to the ASDF team reasonable.
Frankly, I think the call to brigade the ASDF team was out of line and I definitely expect better from a prominent CL developer. Additionally, while I agree that he had the right to not merge the patches, I still think he should have and am upset that he didn't.
There were at least three ways to remove the warning. All three were offered at one point or another. All three were backward compatible (one maybe needed a bit of reader macro magic to be so). Two did not require changing the names of the systems.
I know this developer is competent enough to understand the improvements the new naming scheme brought, so why was he a stick in the mud about it? The technical arguments for the change were strong and a PR was waiting for approval, so the two most obvious explanations are that it was some personal vendetta or he wanted to punish the ASDF developers for not getting the issue correct on the first try and wanted to force us to continue to support a horribly broken feature.
Maybe it was something else, but in any case, it makes me upset that he would prioritize whatever that reason was over supporting another CL project that is attempting to make things easier and more reliable for nearly every CL developer.
That being said, there is one place where I think I disagree with Robert. He said that the CL community tacitly accepts this behavior. But I'm really starting to think that this can't be true because there really is no CL community to speak of.
fe[nl]ix's blog post on IDEs is probably what planted this idea in my head. I didn't believe (or want to believe) it at the time, but the more I've thought about it the more sense it makes. There is no big, happy CL community. Instead there's this diaspora of small communities that only tangentially interact with each other. So it's true that the edicl community tacitly (or explicitly) accepted this behavior. But there are other communities that find the behavior abhorrent. But because they're not the same community, and each community's resources (especially manpower) are finite, there's not much they could do about it. Heck, they may not have known the issue existed until Robert's email!
To be fair, one person in the Reddit thread pointed out there is no CL community. I down voted him at the time, but it was done out of anger and I have since turned it into an up vote. That broke my spirit a bit, but it needed to be done.
This realization is very sobering and distressing. One thing I've learned about myself is that I work the best when part of a supportive community and I am willing to make some personal sacrifices to help my community. I'm lucky enough to have such a community at the moment -- my research group. I've done a lot of work in CL that I didn't need to do for my own personal goals, but I found enjoyable because I was invested in helping others and improving our shared situation and ability to make progress.
However, I won't be a part of this research group forever. So what happens when I look to find a new community? Will I be forced to reside in multiple small, fractured communities? Or is it more likely that I'll drift away from CL forever?
So far, I have found the ASDF community, Robert in particular, to be supportive. But there's a decent chance he's going to resign. I've also found the Common Lisp Foundation folks to be extremely supportive and, like me, willing to take on small personal costs for the greater good. But their reach is somewhat limited (again, mostly due to the low manpower inherent in having many small communities).
But I want more. I want a broader CL community that supports one another, gives constructive feedback, uses each others' projects, and contributes code and issues. I want a community that is willing to make small individual sacrifices in order to improve everyone's situation. I want a community that realizes that because our language is frozen in time, we can devote more efforts to continuously improving our software, even if it means there are breaking changes (so long as those changes are communicated in advance :D). That last one is particularly important to me because, let's face it, most CL projects don't have a brilliant committee designing them and didn't get their interfaces perfect the first time.
So, how do we move forward? For the immediate issue, the edicl community has grown a little bit with the addition of new maintainers. At least some of those new maintainers care about this issue and are working to improve their system definitions.
But how to build a bigger, better CL community escapes me. I personally think the CLF has the best chance at being the seed crystal of such a community. They have a nonprofit set up, they are already providing shared infrastructure (such as Gitlab, project web site hosting (side note: there's some exciting news coming down the pipe soon on that front), mailing lists, and fundraising), and it seems to be run by level-headed folks that truly want to see CL succeed and a community grow. So I highly recommend that more people join that community by taking advantage of what they offer and floating any community building ideas you have on their fora or at their monthly meetings.
Beyond that, I think the best advice may be to try and broaden out any community you find yourself a part of. Give more people commit rights (after making sure they're trustworthy, of course). File issues and PRs instead of forking a project (and be responsive when you receive them!). Plan for project succession by hosting projects in a shared org instead of in your personal namespace. If you've got a single person project, consider hosting it on CLF's Gitlab so that if you drop off the face of the Earth an admin can step in and make sure someone else is able to continue working on it.
If we all grow our communities enough maybe they'll merge and we'll get our one big happy community. Then again, maybe not, but I think it's the best idea I've got at the moment.
via Planet Lisp by on Sun, 09 Jan 2022 23:31:08 GMT
#CommonLisp #Lisp
Let's consider the following function:
(defun make-adder (x huge-p)
(lambda (y) (+ x y (if huge-p 1000 0))))
The result of calling (MAKE-ADDER 10) closes over HUGE-P and makes a runtime check for its value.
CL-USER> (disassemble (make-adder 10 nil))
; disassembly for (LAMBDA (Y) :IN MAKE-ADDER)
; Size: 65 bytes. Origin: #x53730938 ; (LAMBDA (Y) :IN MAKE-ADDER)
; 38: 488975F8 MOV [RBP-8], RSI
; 3C: 488BD3 MOV RDX, RBX
; 3F: E8EC012DFF CALL #x52A00B30 ; GENERIC-+
; 44: 488B75F8 MOV RSI, [RBP-8]
; 48: 4881FE17011050 CMP RSI, #x50100117 ; NIL
; 4F: BFD0070000 MOV EDI, 2000
; 54: B800000000 MOV EAX, 0
; 59: 480F44F8 CMOVEQ RDI, RAX
; 5D: E8CE012DFF CALL #x52A00B30 ; GENERIC-+
; 62: 488BE5 MOV RSP, RBP
; 65: F8 CLC
; 66: 5D POP RBP
; 67: C3 RET
; 68: CC10 INT3 16 ; Invalid argument count trap
; 6A: 6A20 PUSH 32
; 6C: E8FFFA2CFF CALL #x52A00470 ; ALLOC-TRAMP
; 71: 5B POP RBX
; 72: E958FFFFFF JMP #x537308CF
; 77: CC10 INT3 16 ; Invalid argument count trap
NIL
It would be better for performance if the test was only made once, in MAKE-ADDER, rather than on every call of the adder closure. MAKE-ADDER could then return one of two functions depending on whether the check succeeds.
(defun make-adder (x huge-p)
(if huge-p
(lambda (y) (+ x y 1000))
(lambda (y) (+ x y 0))))
A brief look at the disassembly of this fixed version shows us that we're right:
CL-USER> (disassemble (make-adder 10 nil))
; disassembly for (LAMBDA (Y) :IN MAKE-ADDER)
; Size: 21 bytes. Origin: #x53730BC7 ; (LAMBDA (Y) :IN MAKE-ADDER)
; C7: 488BD1 MOV RDX, RCX
; CA: E861FF2CFF CALL #x52A00B30 ; GENERIC-+
; CF: 31FF XOR EDI, EDI
; D1: E85AFF2CFF CALL #x52A00B30 ; GENERIC-+
; D6: 488BE5 MOV RSP, RBP
; D9: F8 CLC
; DA: 5D POP RBP
; DB: C3 RET
NIL
Still, with more flags than one, this style of writing code is likely to become unwieldy. For three flags, we would need to write something like this for the runtime version:
(defun make-adder (x huge-p enormous-p humongous-p)
(lambda (y) (+ x y
(if huge-p 1000 0)
(if enormous-p 2000 0)
(if humongous-p 3000 0))))
But it would look like this for the macroexpand-time version:
(defun make-adder (x huge-p enormous-p humongous-p)
(if huge-p
(if enormous-p
(if humongous-p
(lambda (y) (+ x y 1000 2000 3000))
(lambda (y) (+ x y 1000 2000 0)))
(if humongous-p
(lambda (y) (+ x y 1000 0 3000))
(lambda (y) (+ x y 1000 0 0))))
(if enormous-p
(if humongous-p
(lambda (y) (+ x y 0 2000 3000))
(lambda (y) (+ x y 0 2000 0)))
(if humongous-p
(lambda (y) (+ x y 0 0 3000))
(lambda (y) (+ x y 0 0 0))))))
The total number of combinations for n boolean flags is 2^n, making it hard to write and maintain code with so many branches. This is where WITH-MACROEXPAND-TIME-BRANCHING comes into play. Using it, we can write our code in a way that looks similar to the runtime-check version:
(defun make-adder (x huge-p enormous-p humongous-p)
(with-macroexpand-time-branching (huge-p enormous-p humongous-p)
(lambda (y) (+ x y
(macroexpand-time-if huge-p 1000 0)
(macroexpand-time-if enormous-p 2000 0)
(macroexpand-time-if humongous-p 3000 0)))))
This code gives us the clarity of runtime-checked version and the performance of a macroexpand-time-checked version. A total of eight versions of the body (and therefore, eight possible LAMBDA forms) are generated. At runtime, only one of them is selected, based on the boolean values of the three flags we provided.
Three conditional operators are provided - MACROEXPAND-TIME-IF, MACROEXPAND-TIME-WHEN, and MACROEXPAND-TIME-UNLESS, mimicking the syntax of, respectively, IF, WHEN, and UNLESS.
It is possible to use the variable *MACROEXPAND-TIME-BRANCH-BYPASS* for bypassing macroexpand-time branching; this is useful e.g. when trying to read the macroexpansions or when debugging. If that variable is set to true, the behavior of the macroexpander is modified:
WITH-MACROEXPAND-TIME-BRANCHING expands into a PROGN form,MACROEXPAND-TIME-IF expands into an IF form,MACROEXPAND-TIME-WHEN expands into a WHEN form,MACROEXPAND-TIME-UNLESS expands into an UNLESS form.Trying to use MACROEXPAND-TIME-IF, MACROEXPAND-TIME-WHEN, or MACROEXPAND-TIME-UNLESS outside the lexical environment established by WITH-MACROEXPAND-TIME-BRANCHES will signal a PROGRAM-ERROR.
Trying to use a branch name MACROEXPAND-TIME-IF, MACROEXPAND-TIME-WHEN, or MACROEXPAND-TIME-UNLESS that wasn't declared in WITH-MACROEXPAND-TIME-BRANCHES will signal a PROGRAM-ERROR.
Grab the code from GitHub.
via Erlang/OTP | News by Kenneth Lundin on Wed, 15 Dec 2021 00:00:00 GMT
via Elm - Latest posts by @supermario Mario Rogic on Wed, 01 Dec 2021 00:51:44 GMT
The videos from the last Elm Online Meetup are now up! 
The next Elm Online Meetup can be found here.
Introduction to elm-charts by Tereza Sokol:
https://www.youtube.com/embed/D-WaKYJLsFU
Peeling zeroes in Idris by Ju Liu:
via Elm - Latest posts by @miniBill Leonardo Taglialegne on Tue, 30 Nov 2021 18:27:21 GMT
I think line 32 and 14 are basically the same thing?
Excellent work with the analysis!
via Elm - Latest posts by @dillonkearns Dillon Kearns on Tue, 30 Nov 2021 16:42:25 GMT
What’s the difference between a violin and a vuvuzela? And what does that have to do with Elm? I wrote a post to explore that burning question in depth.
via Elm - Latest posts by @gampleman Jakub Hampl on Tue, 30 Nov 2021 15:56:32 GMT
Fundamentally there seems to be more than one way to skin a cat.
In the broader view you’re gonna go somewhere between the simplicity of the for loop and the efficiency of SQL depending on your needs in terms of optimisation, composition and predictability.
I think the cool thing about transducers is that they provide a very cool interface for the fromList/toList stuff that is entirely abstracted from the datastrucutre (as long as it has some neccesary operations).
via Elm - Latest posts by @mattpiz Matthieu Pizenberg on Tue, 30 Nov 2021 14:32:43 GMT
Transducers seems to be quite similar to iterators like Iter - elm-iter 1.0.0 for the purpose of computing multiple transformations before reducing. Do you know of good resources explaining the fundamental differences? I feel like transducers are more powerful since I remember reading about those when I was looking for operations that could mutate data in place in a type-safe way but I haven’t look at those things for a long time …
via Elm - Latest posts by @rupert Rupert Smith on Tue, 30 Nov 2021 11:27:50 GMT
You could kind of say that all Linux distros are releases of the upstream Linux kernel - I know its stretching the analogy with Elm a bit, but …
Each Linux distro has its own name, logo and identity. They all feed from a huge number of upstream projects and try to bring them together into a stable curated system. They all create opportunities to feedback patches to those upstream projects. Some have their own private repos and kernel patches (but must make those available as per the GPL) - RedHat Enterprise Linux being the obvious example.
Would put a different name and logo on it, but be completely open about the fact that it is actually Elm with a few modifications.
via Elm - Latest posts by @gampleman Jakub Hampl on Tue, 30 Nov 2021 10:05:55 GMT
It’s also fairly straightforward to write a library that does this in user land.
via Elm - Latest posts by @jfmengels Jeroen Engels on Tue, 30 Nov 2021 09:20:18 GMT
It’s not part of elm-review-simplify because this is not a simplification 100% of the time in terms of readability.
a
|> List.map toX
|> List.map toY
may be more readable than
a
|> List.map (toX >> toY)
especially for people who dislike or have trouble reading >>. Also, in some cases, things get pretty
a
|> List.map toX
|> List.map
(if condition then
toY
else
identity
)
would become
a
|> List.map
(toX
>> (if condition then
toY
else
identity
)
)
which I believe is worse (not that the former was that much better though).
The Elm compiler actually does very little work transforming the code. As far as I can tell, it transforms things like +into real additions (instead of function calls) and |> into regular function calls, and that’s the extent to which the compiler optimizes things (and it’s already really fast  ).
).
I am currently looking into merging map functions and the sorts together through elm-optimize-level-2. If it works out well, then hopefully it will make it into the compiler at one point. From preliminary benchmarks, it does look like it improves performance.
That said, there is a problem with optimizing Elm core code like this, which is that custom code won’t receive the same optimizations. Say you wrote a thin wrapper around List named MyList to enforce some constraints. If the compiler were to optimize a |> List.map f |> List.map g, it wouldn’t do the same thing for a |> MyList.map f |> MyList.map g, because the compiler doesn’t know how this map function works.
And the same thing applies for other kinds of optimizations. If you want to benefit from the same optimizations because MyList is used in performance-critical code, you’d need to remove the wrapper and start using List, which is not an incentive for good and maintainable code.
It’s like having regular-speed car lanes on a highway for almost everything in Elm, and then a fast lane for core custom types. Once you have a fast lane, the other lanes become slow lanes.
Does this mean we shouldn’t apply this transformation? Not necessarily, but it’s something to keep in mind. I believe we should try and find ways to make all lanes fast, but that will probably be hard.
via Elm - Latest posts by @madsh Mads Hjorth on Tue, 30 Nov 2021 07:18:39 GMT
Thanks to @RyanNHG and @DullBananas for such a swift answer!
Being a lazy programmer, I went with the shorter solution.
I tried to go to ‘innerspa.html’ using a Browser.Navigation.load "innerspa.html" in the update section and it worked like a charm.
Not too bad for a bunch of blunt fruits 
And I guess I learned a bit about http routing on Netlify, if I ever wanted to access the innerspa.html directly from a URL and not coming from my “outerspa”.
via Elm - Latest posts by @RyanNHG Ryan Haskell Glatz on Tue, 30 Nov 2021 03:13:51 GMT
Hey @madsh,
How you serve static pages in elm-spa will depend on what hosting looks like for you.
For single page apps, there is a requirement to redirect all requests to the single index.html file. For example, when I was making https://elm-spa.dev, I chose to host the app with Netlify.
Here’s what my netlify.toml file looked like to handle single-page redirects:
The last [[redirects]] section takes all page requests and points them to index.html (which serves the elm-spa application). This is what makes URL requests to /posts or /about-me always hit the elm-spa application.
If you were using Netlify, and wanted requests to /innerspa/* to go to a different entrypoint- you would specify a section like this before the final index.html redirect:
[[redirects]]
from = "/innerspa/*"
to = "/innerspa.html"
status = 200
As long as your innerspa.html file is alongside index.html in the public folder, you should be all set.
If you are using a different server than Netlify, you’ll need to look into the docs for that hosting solution. The good news is this is a general frontend web app problem, so what you learn there will apply to elm-spa and any other frontend project you use. 
Hope this context helps!
Ryan