Feed Aggregator Page 673
Rendered on Thu, 25 Nov 2021 18:33:57 GMT
|
|
Lisplog |
Rendered on Thu, 25 Nov 2021 18:33:57 GMT
via Elm - Latest posts by @AvailableUsername on Mon, 22 Nov 2021 16:04:45 GMT

I think the problem is that you have no way to represent variables in your syntax trees.
You could add variables to your Expression type.
type Expression
= Call CallExpression
| Todo
| NumberLiteral Float
| Variable String
or, even, if you have a small number of possible variables (say, X and Y):
type Expression
= Call CallExpression
| Todo
| NumberLiteral Float
| X
| Y
Then maintain a mapping of variables to values and use that mapping when doing computations with your trees.
In the first case (variables as strings):
type alias Mapping = Dict String Float
In the second case (just two variables X and Y):
type alias Mapping = { x: Float, y: Float}
via Elm - Latest posts by @jfmengels Jeroen Engels on Mon, 22 Nov 2021 15:23:30 GMT
 Elm Radio Episode 044: elm-webgl is out!
Elm Radio Episode 044: elm-webgl is out!
We are joined this time by Andrey Kuzmin (@unsoundscapes) who walks us through Elm’s syntax for writing 3D shaders and using them in a type-safe way from Elm.
We hope you enjoy the episode!
via Elm - Latest posts by @raephee2 on Mon, 22 Nov 2021 15:17:55 GMT
I found a clue. I used Wireshark to listen to the network traffic while running elm-json. I captured a Certificate Expired error. However, when I go to the website in any browser, it shows a valid certificate.


I tried to connect to https://package.elm-lang.org via the Python shell and that worked well. So somehow the OSX binary of elm-json has some issue, I guess.
via Elm - Latest posts by @raephee2 on Mon, 22 Nov 2021 14:32:33 GMT
Thanks for the hint. Now it breaks with another package.
❯ rm -rf ~/.elm
❯ npx elm-json -vv solve
phase: retrieve
Nov 22 15:30:48.789 DEBG Fetching versions since 0
Nov 22 15:30:49.184 WARN Failed to fetch versions from package.elm-lang.org
phase: resolve
Nov 22 15:30:49.185 INFO beginning dependency resolution
phase: retrieve
Nov 22 15:30:49.185 DEBG Finding best version for package root with constraint 1.0.0
Nov 22 15:30:49.185 DEBG Finding best version for package NoRedInk/elm-json-decode-pipeline with constraint 1.0.0
phase: resolve
Nov 22 15:30:49.185 INFO Failed to add package NoRedInk/elm-json-decode-pipeline 1.0.0: Unknown package NoRedInk/elm-json-decode-pipeline
Nov 22 15:30:49.185 INFO solve failed
-- NO VALID PACKAGE VERSION ----------------------------------------------------
Because NoRedInk/elm-json-decode-pipeline does not appear to exist and this
project depends on NoRedInk/elm-json-decode-pipeline 1.0.0, no valid set of
package versions could be found.
It seems if it couldn’t access the package repo. I wonder how I can debug that.
via Planet Lisp by on Mon, 22 Nov 2021 12:36:25 GMT
Someone asked about better Lisp IDEs on reddit. Such things would obviously be desirable. But the comments are entirely full the usual sad endless droning from people who need there always to be something preventing them from doing what they pretend to want to do, and are happy to invent such barriers where none really exist. comp.lang.lisp lives on in spirit if not in fact.
[The rest of this article is a lot ruder than the above and I’ve intentionally censored it from the various feeds. See also corrections and clarifications.]
More…
via Planet Lisp by on Sat, 20 Nov 2021 00:00:00 GMT
Although Verbose is one of few logging libraries that work with threaded applications (See Comparison of Common Lisp Logging Libraries), I had some trouble getting it to work in my application. I have a Hunchentoot web application which handles each request in a separate thread that is built as a standalone executable. Getting Verbose to work in Slime was trivial but once I built the standalone, it kept crashing.
The Verbose documentation provides all the information needed to make this setup work but not in a step-by-step fashion so this took me some time to figure out.
To work with threaded applications Verbose must run inside a thread of its own. It tries to make life easier for the majority case by starting its thread as soon as it is loaded. Creating a standalone application requires that the running lisp image contains only a single running thread. The Verbose background thread prevents the binary from being built. This can be remedied by preventing Verbose from immediately starting its background thread and then manually start it inside the application.
When Verbose is loaded inside Slime it prints to the REPL's *standard-output*
without fuss but when I loaded it inside my standalone binary it caused the
application to crash. I did not investigate the *standard-output* connection
logic but I discovered that you must tell Verbose explicitly about the current
*standard-output* in a binary otherwise it won't work.
Steps:
(pushnew :verbose-no-init *features*)
This feature must be set before the Verbose system is loaded. It prevents Verbose from starting its main background thread, which it does by default immediately when it is loaded.
I added this form in the .asd file immediately before my application
system definition. While executing code inside the .asd file is considered
bad style it provided the cleanest way for me to do this otherwise I would
have to do it in multiple places to cover all the use cases for development
flows and building the production binary. There may be a better way to set
*features* before a system is loaded but I have not yet discovered it.
(v:output-here *standard-output*)
This form makes Verbose use the *standard-output* as it currently
exists. Leaving out this line was the cause of my application crashes. I am
not sure what the cause is but I suspect Verbose tries to use Slime's
version of *standard-output* if you don't tell it otherwise, even when it
is not running in Slime.
This must be done before starting the Verbose background thread.
(v:start v:*global-controller*)
Start the Verbose background thread.
(v:info :main "Hello world!")
Start logging.
I use systemd to run my applications. Systemd recommends that applications run
in the foreground and print logs to the standard output. The application output
is captured and logged in whichever way systemd is configured. On default
installations this is usually in /var/log/syslog in the standard logging
format which prepends the timestamp and some other information. Verbose also by
default prints the timestamp in the logged message, which just adds noise and
makes syslog difficult to read.
Verbose's logging format can be configured to be any custom format by
subclassing its message class and providing the proper formatting
method. This must be done before any other Verbose configuration.
Combining all the code looks like below.
In app.asd:
(pushnew :verbose-no-init *features*)
(defsystem #:app
...)
In app.lisp:
(defclass log-message (v:message) ())
(defmethod v:format-message ((stream stream) (message log-message))
(format stream "[~5,a] ~{<~a>~} ~a"
(v:level message)
(v:categories message)
(v:format-message NIL (v:content message))))
(defun run ()
(setf v:*default-message-class* 'log-message)
(v:output-here *standard-output*)
(v:start v:*global-controller*)
(v:info :main "Hello world!")
...)
via Planet Lisp by on Sat, 13 Nov 2021 07:11:24 GMT
Hi, all Common Lispers.
In the previous article, I introduced the management of Lisp implementations with Roswell.
One of the readers asked me how to install Roswell itself. Sorry, I forgot to mention it. Please look into the official article at GitHub Wiki. Even on Windows, it recently has become possible to install it with a single command. Quite easy.
Today, I'm going to continue with Roswell: the installation of Common Lisp libraries and applications.
Quicklisp is the de-facto library registry. When you install Roswell, the latest versions of SBCL and Quicklisp are automatically set up.
Let's try to see the value of ql:*quicklisp-home* in REPL to check where Quicklisp is loaded from.
$ ros run
* ql:*quicklisp-home*
#P"/home/fukamachi/.roswell/lisp/quicklisp/"
You see that Quicklisp is installed in ~/.roswell/lisp/quicklisp/.
To install a Common Lisp project using this Quicklisp, execute ros install command:
# Install a project from Quicklisp dist
$ ros install <project name>
You probably remember ros install command is also used to install Lisp implementations. If you specify something other than the name of implementations, Roswell assumes that it's the name of an ASDF project. If the project is available in Quicklisp dist, it will be installed from Quicklisp.
Installed files will be placed under ~/.roswell/lisp/quicklisp/dists/quicklisp/software/ along with its dependencies.
If it's installed from Quicklisp, it may seem to be the same as ql:quickload. So you would think that this is just a command to be run from the terminal.
In most cases, that's true. However, if the project being installed contains some command-line programs with the directory named roswell/, Roswell will perform an additional action.
For example, Qlot provides qlot command. By running ros install qlot, Roswell installs the executable at ~/.roswell/bin/qlot.
This shows that Roswell can be used as an installer not only for simple projects but also for command-line applications.
Other examples of such projects are "lem", a text editor written in Common Lisp, and "mondo", a REPL program.
I'll explain how to write such a project in another article someday.
How about installing a project that is not in Quicklisp? Or, in some cases, the monthly Quicklisp dist is outdated, and you may want to use the newer version.
By specifying GitHub's user name and project name for ros install, you can install the project from GitHub.
$ ros install <user name>/<project name>
# In the case of Qlot
$ ros install fukamachi/qlot
Projects installed from GitHub will be placed under ~/.roswell/local-projects.
To update it, run ros update:
# Note that it is not "fukamachi/qlot".
$ ros update qlot
Besides, you can also install a specific version by specifying a tag name or a branch name.
# Install Qlot v0.11.4 (tag name)
$ ros install fukamachi/qlot/0.11.4
# Install the development version (branch name)
$ ros install fukamachi/qlot/develop
How about installing a project that doesn't exist in both Quicklisp and GitHub?
It's also easy. Just place the files under ~/.roswell/local-projects, and run ros install <project name>.
Let me explain a little about how it works.
This mechanism is based on the local-projects mechanism provided by Quicklisp.
The "~/.roswell/local-projects" directory can be treated just like the local-projects directory of Quicklisp.
As a side note, if you want to treat other directories like local-projects, just add the path to ros:*local-project-directories*. This is accomplished by adding Roswell-specific functions to asdf:*system-definition-search-functions*. Check it out if you are interested.
You can place your personal projects there or symbolically link to them to make them loadable.
But, I personally think that this directory should be used with caution.
Projects placed under the local-projects directory can be loaded immediately after starting the REPL. I suppose many users use it for this convenience.
However, this becomes a problem when developing multiple projects on the same machine. Quicklisp's "local-projects" directory is user-local. Which means all projects will share it. Therefore, even if you think you are loading from Quicklisp, you may be loading a previously installed version from GitHub.
To avoid these dangers, I recommend using Qlot. If you are interested, please look into it.
Anyway, it is better to keep the number of local-projects to a minimum to avoid problems.
If you suspect that an unintended version of the library is loaded, you can check where the library is loaded by executing (ql:where-is-system :<project name>).
I introduced how to install Common Lisp projects with Roswell.
ros install <project name>ros install <user name>/<project name>ros install <user name>/<project name>/<tag>ros install <user name>/<project name>/<branch>~/.roswell/local-projects
via Planet Lisp by on Thu, 11 Nov 2021 14:32:11 GMT
People learning Lisp often try to learn how to write macros by taking an existing function they have written and turning it into a macro. This is a mistake: macros and functions serve different purposes and it is almost never useful to turn functions into macros, or macros into functions.
Let’s say you are learning Common Lisp1, and you have written a fairly obvious factorial function based on the natural mathematical definition: if \(n \in \mathbb{N}\), then
\[ n! = \begin{cases} 1 &n \le 1\\ n \times (n - 1)! &n > 1 \end{cases} \]
So this gives you a fairly obvious recursive definition of factorial:
(defun factorial (n)
(if (<= n 1)
1
(* n (factorial (1- n )))))And so, you think you want to learn about macros so can you write factorial as a macro? And you might end up with something like this:
(defmacro factorial (n)
`(if (<= ,n 1)
1
(* ,n (factorial ,(1- n )))))And this superficially seems as if it works:
> (factorial 10)
3628800But it doesn’t, in fact, work:
> (let ((x 3))
(factorial x))
Error: In 1- of (x) arguments should be of type number.Why doesn’t this work and can it be fixed so it does? If it can’t what has gone wrong and how are macros meant to work and what are they useful for?
It can’t be fixed so that it works. trying to rewrite functions as macros is a bad idea, and if you want to learn what is interesting about macros you should not start there.
To understand why this is true you need to understand what macros actually are in Lisp.
A macro is a function whose domain and range is syntax.
Macros are functions (quite explicitly so in CL: you can get at the function of a macro with macro-function, and this is something you can happily call the way you would call any other function), but they are functions whose domain and range is syntax. A macro is a function whose argument is a language whose syntax includes the macro and whose value, when called on an instance of that language, is a language whose syntax doesn’t include the macro. It may work recursively: its value may be a language which includes the same macro but in some simpler way, such that the process will terminate at some point.
So the job of macros is to provide a family of extended languages built on some core Lisp which has no remaining macros, only functions and function application, special operators & special forms involving them and literals. One of those languages is the language we call Common Lisp, but the macros written by people serve to extend this language into a multitude of variants.
As an example of this I often write in a language which is like CL, but is extended by the presence of a number of extra constructs, one of which is called ITERATE (but it predates the well-known one and is not at all the same):
(iterate next ((x 1))
(if (< x 10)
(next (1+ x))
x)is equivalent to
(labels ((next (x)
(if (< x 10)
(next (1+ x))
x)))
(next 1))Once upon a time when I first wrote iterate, it used to manually optimize the recursive calls to jumps in some cases, because the Symbolics I wrote it on didn’t have tail-call elimination. That’s a non-problem in LispWorks2. Anyone familiar with Scheme will recognise iterate as named let, which is where it came from (once, I think, it was known as nlet).
iterate is implemented by a function which maps from the language which includes it to a language which doesn’t include it, by mapping the syntax as above.
So compare this with a factorial function: factorial is a function whose domain is natural numbers and whose range is also natural numbers, and it has an obvious recursive definition. Well, natural numbers are part of the syntax of Lisp, but they’re a tiny part of it. So implementing factorial as a macro is, really, a hopeless task. What should
(factorial (+ x y (f z)))Actually do when considered as a mapping between languages? Assuming you are using the recursive definition of the factorial function then the answer is it can’t map to anything useful at all: a function which implements that recursive definition simply has to be called at run time. The very best you could do would seem to be this:
(defun fact (n)
(if (< n 3)
n
(* n (fact (1- n)))))
(defmacro factorial (expression)
`(fact ,expression))And that’s not a useful macro (but see below).
So the answer is, again, that macros are functions which map between languages and they are useful where you want a new language: not just the same language with extra functions in it, but a language with new control constructs or something like that. If you are writing functions whose range is something which is not the syntax of a language built on Common Lisp, don’t write macros.
Macroexpansion is compilation.
A function whose domain is one language and whose range is another is a compiler for the language of the domain, especially when that language is somehow richer than the language of the range, which is the case for macros.
But it’s a simplification to say that macros are this function: they’re not, they’re only part of it. The actual function which maps between the two languages is made up of macros and the macroexpander provided by CL itself. The macroexpander is what arranges for the functions defined by macros to be called in the right places, and also it is the thing which arranges for various recursive macros to actually make up a recurscive function. So it’s important to understand that the macroexpander is a critical part of the process: macros on their own only provide part of it.
People often say that you should not write recursive macros, but this prohibition on recursive macros is pretty specious: they’re just fine. Consider a language which only has lambda and doesn’t have let. Well, we can write a simple version of let, which I’ll call bind as a macro: a function which takes this new language and turns it into the more basic one. Here’s that macro:
(defmacro bind ((&rest bindings) &body forms)
`((lambda ,(mapcar #'first bindings) ,@forms)
,@(mapcar #'second bindings)))And now
> (bind ((x 1) (y 2))
(+ x y))
(bind ((x 1) (y 2)) (+ x y))
-> ((lambda (x y) (+ x y)) 1 2)
3(These example expansions come via use of my trace-macroexpand package, available in a good Lisp near you: see appendix for configuration).
So now we have a language with a binding form which is more convenient than lambda. But maybe we want to be able to bind sequentially? Well, we can write a let* version, called bind*, which looks like this
(defmacro bind* ((&rest bindings) &body forms)
(if (null (rest bindings))
`(bind ,bindings ,@forms)
`(bind (,(first bindings))
(bind* ,(rest bindings) ,@forms))))And you can see how this works: it checks if there’s just one binding in which case it’s just bind, and if there’s more than one it peels off the first and then expands into a bind* form for the rest. And you can see this working (here both bind and bind* are being traced):
> (bind* ((x 1) (y (+ x 2)))
(+ x y))
(bind* ((x 1) (y (+ x 2))) (+ x y))
-> (bind ((x 1)) (bind* ((y (+ x 2))) (+ x y)))
(bind ((x 1)) (bind* ((y (+ x 2))) (+ x y)))
-> ((lambda (x) (bind* ((y (+ x 2))) (+ x y))) 1)
(bind* ((y (+ x 2))) (+ x y))
-> (bind ((y (+ x 2))) (+ x y))
(bind ((y (+ x 2))) (+ x y))
-> ((lambda (y) (+ x y)) (+ x 2))
(bind* ((y (+ x 2))) (+ x y))
-> (bind ((y (+ x 2))) (+ x y))
(bind ((y (+ x 2))) (+ x y))
-> ((lambda (y) (+ x y)) (+ x 2))
4You can see that, in this implementation, which is LW again, some of the forms are expanded more than once: that’s not uncommon in interpreted code: since macros should generally be functions (so, not have side-effects) it does not matter that they may be expanded multiple times. Compilation will expand macros and then compile the result, so all the overhead of macroexpansion happend ahead of run-time:
(defun foo (x)
(bind* ((y (1+ x)) (z (1+ y)))
(+ y z)))
foo
> (compile *)
(bind* ((y (1+ x)) (z (1+ y))) (+ y z))
-> (bind ((y (1+ x))) (bind* ((z (1+ y))) (+ y z)))
(bind ((y (1+ x))) (bind* ((z (1+ y))) (+ y z)))
-> ((lambda (y) (bind* ((z (1+ y))) (+ y z))) (1+ x))
(bind* ((z (1+ y))) (+ y z))
-> (bind ((z (1+ y))) (+ y z))
(bind ((z (1+ y))) (+ y z))
-> ((lambda (z) (+ y z)) (1+ y))
foo
nil
nil
> (foo 3)
9There’s nothing wrong with macros like this, which expand into simpler versions of themselves. You just have to make sure that the recursive expansion process is producing successively simpler bits of syntax and has a well-defined termination condition.
Macros like this are often called ‘recursive’ but they’re actually not: the function associated with bind* does not call itself. What is recursive is the function implicitly defined by the combination of the macro function and the macroexpander: the bind* function simply expands into a bit of syntax which it knows will cause the macroexpander to call it again.
It is possible to write bind* such that the macro function itself is recursive:
(defmacro bind* ((&rest bindings) &body forms)
(labels ((expand-bind (btail)
(if (null (rest btail))
`(bind ,btail
,@forms)
`(bind (,(first btail))
,(expand-bind (rest btail))))))
(expand-bind bindings)))And now compiling foo again results in this output from tracing macroexpansion:
(bind* ((y (1+ x)) (z (1+ y))) (+ y z))
-> (bind ((y (1+ x))) (bind ((z (1+ y))) (+ y z)))
(bind ((y (1+ x))) (bind ((z (1+ y))) (+ y z)))
-> ((lambda (y) (bind ((z (1+ y))) (+ y z))) (1+ x))
(bind ((z (1+ y))) (+ y z))
-> ((lambda (z) (+ y z)) (1+ y))You can see that now all the recursion happens within the macro function for bind* itself: the macroexpander calls bind*’s macro function just once.
While it’s possible to write macros like this second version of bind*, it is normally easier to write the first version and to allow the combination of the macroexpander and the macro function to implement the recursive expansion.
There are two uses for macros — both now historical — where they were used where functions would be more natural.
The first of these is function inlining, where you want to avoid the overhead of calling a small function many times. This overhead was a lot on computers made of cardboard, as all computers were, and also if the stack got too deep the cardboard would tear and this was bad. It makes no real sense to inline a recursive function such as the above factorial: how would the inlining process terminate? But you could rewrite a factorial function to be explicitly iterative:
(defun factorial (n)
(do* ((k 1 (1+ k))
(f k (* f k)))
((>= k n) f)))And now, if you have very many calls to factorial, you wanted to optimise the function call overhead away, and it was 1975, you might write this:
(defmacro factorial (n)
`(let ((nv ,n))
(do* ((k 1 (1+ k))
(f k (* f k)))
((>= k nv) f))))And this has the effect of replacing (factorial n) by an expression which will compute the factorial of n. The cost of that is that (funcall #'factorial n) is not going to work, and (funcall (macro-function 'factorial) ...) is never what you want.
Well, that’s what you did in 1975, because Lisp compilers were made out of the things people found down the sides of sofas. Now it’s no longer 1975 and you just tell the compiler that you want it to inline the function, please:
(declaim (inline factorial))
(defun factorial (n) ...)and it will do that for you. So this use of macros is now purely historicl.
The second reason for macros where you really want functions is computing things at compile time. Let’s say you have lots of expressions like (factorial 32) in your code. Well, you could do this:
(defmacro factorial (expression)
(typecase expression
((integer 0)
(factorial/fn expression))
(number
(error "factorial of non-natural literal ~S" expression))
(t
`(factorial/fn ,expression))))So the factorial macro checks to see if its argument is a literal natural number and will compute the factorial of it at macroexpansion time (so, at compile time or just before compile time). So a function like
(defun foo ()
(factorial 32))will now compile to simply return 263130836933693530167218012160000000. And, even better, there’s some compile-time error checking: code which is, say, (factorial 12.3) will cause a compile-time error.
Well, again, this is what you would do if it was 1975. It’s not 1975 any more, and CL has a special tool for dealing with just this problem: compiler macros.
(defun factorial (n)
(do* ((k 1 (1+ k))
(f k (* f k)))
((>= k n) f)))
(define-compiler-macro factorial (&whole form n)
(typecase n
((integer 0)
(factorial n))
(number
(error "literal number is not a natural: ~S" n))
(t form)))Now factorial is a function and works the way you expect — (funcall #'factoial ...) will work fine. But the compiler knows that if it comes across (factorial ...) then it should give the compiler macro for factorial a chance to say what this expression should actually be. And the compiler macro does an explicit check for the argument being a literal natural number, and if it is computes the factorial at compile time, and the same check for a literal number which is not a natural, and finally just says ’I don’t know, call the function’. Note that the compiler macro itself calls factorial, but since the argument isn’t a literal there’s no recursive doom.
So this takes care of the other antique use of macros where you would expect functions. And of course you can combine this with inlining and it will all work fine: you can write functions which will handle special cases via compiler macros and will otherwise be inlined.
That leaves macros serving the purpose they are actually useful for: building languages.
trace-macroexpand(use-package :org.tfeb.hax.trace-macroexpand)
;;; Don't restrict print length or level when tracing
(setf *trace-macroexpand-print-level* nil
*trace-macroexpand-print-length* nil)
;;; Enable tracing
(trace-macroexpand)
;;; Trace the macros you want to look at ...
(trace-macro ...)
;;; ... and ntrace them
(untrace-macro ...)All the examples in this article are in Common Lisp except where otherwise specified. Other Lisps have similar considerations, although macros in Scheme are not explicitly functions in the way they are in CL. ↩
This article originated as a message on the lisp-hug mailing list for LispWorks users. References to ‘LW’ mean LispWorks, although everything here should apply to any modern CL. (In terms of tail call elimination I would define a CL which does not eliminate tail self-calls in almost all cases under reasonable optimization settings as pre-modern: I don’t use such implementations.) ↩
via Planet Lisp by on Sun, 07 Nov 2021 17:50:38 GMT
An event-ful month passed by for Kandria! Lots of developments in terms of conferences and networking. This, in addition to falling ill for a few days, left little time for actual dev again, though even despite everything we still have some news to share on that front as well!
One of the major events this month was the Swiss-Polish game jam alongside GIC, which was organised largely by the Swiss embassy in Poland. Tim and I partnered up with three good fellows from Blindflug Studios, and made a small game called Eco Tower. The jam lasted only 48 hours, so it's nothing grand, but I'm still quite happy with how it turned out, and it was a blast working with the rest of the team!
You can find the game on itch.io.
The Game Industry Conference was pretty great! I had a fun time talking to the rest of Pro Helvetia and the other delegated teams, as well as the various attendees that checked out our booth. I wrote a lot more about it and the game jam in a previous weekly mailing list update, which, as an exception, you can see here.
Over the course of our Poland visit we were also informed that we'd been accepted into the Digital Dragons Accelerator programme, which is very exciting! Digital Dragons is a Polish conference and organisation to support games, and with this new accelerator programme they're now also reaching out to non-polish developers to support their projects. Only 13 teams out of 97 from all over Europe were chosen, so we're really happy to have been accepted!
As part of the programme we'll be partnered with a Polish publishing company to settle on and then together achieve a set of milestones, over which the grant money of over 50k€ will be paid out. The partner will not be our publisher, just a partner, for the duration of this programme.
Now, you may be wondering what's in it for Poland, as just handing out a load of money to external studios sounds a bit too good to be true, and indeed there's a small catch. As part of the programme we have to first establish a company in Poland, to which the grant will be paid out, and with the hopes that you'll continue using this company after the accelerator ends. We're now in the process of establishing this company, and have already signed a contract with a law firm to help us out with everything involved.
In any case, this is all very exciting, and I'm sure we'll have more to share about all of this as time goes on.
Then this week was the Nordic Games Winter conference, with another MeetToMatch platform. We were also accepted into its "publisher market", which had us automatically paired up with 10 publishing firms for pitches on Tuesday. That, combined with law firm meetings, meant that on Tuesday I had 12 meetings almost back to back. Jeez!
I'm not hedging my bets on getting any publishing deals out of this yet, but it is still a great opportunity to grow our network and get our name and game out there into the collective mind of the industry. The response from the recruiters also generally seems favourable, which is really cool.
I do wish we had a new trailer though. While I still think our current VS trailer is good, I've now had to listen to it so many times during pitches and off that I really can't stand it anymore, ha ha! We'll hold off on that though, creating new content and hammering out that horizontal slice is far more important at this stage.
There was a hotfix release along the line that clears out a bunch of critical bugs, and adds a few small features as well. You can get it from your usual link, or by signing up.
We're now well into the horizontal slice development, and I've started hammering out the level design for the lower part of region 1. I'm still very slow-going on that since I just lack the experience to do it easily, which in turn makes me loathe doing it, which in turn makes me do less of it, which in turn does not help my experience. Woe is me! Anyway, I'll just grit my teeth for now and get as much done as I can - I'll get better over time I'm sure!
As part of the level design process I've also started implementing more platforming mechanics such as the slide move, lava and oil liquids, a dash-recharge element, and recallable elevators. I'll have to add a few more things still, such as crumbling platforms, springs and springboards, wind, exhaust pipes, and conveyor belts.
This month has been horizontal slice quest development, with the trip to Poland for GIC sandwiched in the middle. I'm sure Nick has covered this in depth above, but I wanted to add that it was an amazing experience for me: travelling to Poland and seeing a new country and culture (St. Martin's croissants / Rogals are AMAZING); the game jam where although as a writer I was somewhat limited (helped a bit with design, research and playtesting), it was nevertheless a great experience with the best result - and I got to shake hands with the Swiss ambassador!; the GIC conference itself, where it was a great feeling with Kandria live on the show floor, and watching players and devs get absorbed; the studio visit with Vile Monarch and 11 bit (Frostpunk is one of my favourite games). But the best thing was the people: getting to meet Nick in real life and see the man behind the magic, not to mention all the other devs, industry folk, and organisers from Switzerland and Poland. It was a real privilege to be part of the group.
I've also been continuing to help with the meet-to-match platform for both GIC, and Nordic Game this past week, filtering publishers to suit our needs and booking meetings. Aside from that, it's now full steam ahead on the horizontal slice! With the quest document updated with Nick's feedback, it's a strong roadmap for me to follow. I'm now back in-game getting my hands dirty with the scripting language - it feels good to be making new content, and pushing the story into the next act beyond the vertical slice.
Fred's been very busy implementing the new moves for the Stranger, as well as doing all the animations for new NPC characters that we need in the extended storyline. One thing I'm very excited about is the generic villagers, as I want to add a little AI to them to make them walk about and really make the settlements feel more alive!
Similarly, Mikel's been hard at work finalising the tracks for the next regions and producing variants for the different levels of tension. I'm stoked to see how they'll work in-game! Here's a peek at one of the tracks:
I'll take this moment to indulge in a little side project. For some years now I've been producing physical desktop calendars, with my own art, design, and distribution thereof. If you like the art I make or would simply like to support what we do and get something small out of it, consider get one on Gumroad.
As always, let's look at the roadmap from last month.
Fix reported crashes and bugs
Add a update notice to the main screen to avoid people running outdated versions
Implement some more accessibility options
Implement more combat and platforming moves
Implement RPG mechanics for levelling and upgrades (partially done)
Explore platforming items and mechanics (partially done)
Practise platforming level design (partially done)
Draft out region 2 main quest line levels and story
Draft out region 3 main quest line levels and story
Complete the horizontal slice
Well, we're starting to crunch away at that horizontal slice content. Still got a long way to go, though!
As always, I sincerely hope you give the new demo a try if you haven't yet. Let us know what you think when you do or if you have already!
via Planet Lisp by on Wed, 03 Nov 2021 12:03:44 GMT
People sometimes ask which is the best Lisp dialect? That’s a category error, and here’s why.
Programming in Lisp — any Lisp — is about building languages: in Lisp the way you solve a problem is by building a language — a jargon, or a dialect if you like — to talk about the problem and then solving the problem in that language. Lisps are, quite explicitly, language-building languages.
This is, in fact, how people solve large problems in all programming languages: Greenspun’s tenth rule isn’t really a statement about Common Lisp, it’s a statement that all sufficiently large software systems end up having some hacked-together, informally-specified, half-working language in which the problem is actually solved. Often people won’t understand that the thing they’ve built is in fact a language, but that’s what it is. Everyone who has worked on large-scale software will have come across these things: often they are very horrible, and involve much use of language-in-a-string1.
The Lisp difference is two things: when you start solving a problem in Lisp, you know, quite explicitly, that this is what you are going to do; and the language has wonderful tools which let you incrementally build a series of lightweight languages, ending up with one or more languages in which to solve the problem.
So, after that preface, why is this question the wrong one to ask? Well, if you are going to program in Lisp you are going to be building languages, and you want those languages not to be awful. Lisp makes it it far easier to build languages which are not awful, but it doesn’t prevent you doing so if you want to. And again, anyone who has dealt with enough languages built on Lisps will have come across some which are, in fact, awful.
If you are going to build languages then you need to understand how languages work — what makes a language habitable to its human users (the computer does not care with very few exceptions). That means you will need to be a linguist. So the question then is: how do you become a linguist? Well, we know the answer to that, because there are lots of linguists and lots of courses on linguistics. You might say that, well, those people study natural languages, but that’s irrelevant: natural languages have been under evolutionary pressure for a very long time and they’re really good for what they’re designed for (which is not the same as what programming languages are designed for, but the users — humans — are the same).
So, do you become a linguist by learning French? Or German? Or Latin? Or Cuzco Quechua? No, you don’t. You become a linguist by learning enough about enough languages that you can understand how languages work. A linguist isn’t someone who speaks French really well: they’re someone who understands that French is a Romance language, that German isn’t but has many Romance loan words, that English is closer to German than it is French but got a vast injection of Norman French, which in turn wasn’t that close to modern French, that Swiss German has cross-serial dependencies but Hochdeutsch does not and what that means, and so on. A linguist is someone who understands things about the structure of languages: what do you see, what do you never see, how do different languages do equivalent things? And so on.
The way you become a linguist is not by picking a language and learning it: it’s by looking at lots of languages enough to understand how they work.
If you want to learn to program in Lisp, you will need to become a linguist. The very best way to ensure you fail at that is to pick a ‘best’ Lisp and learn that. There is no best Lisp, and in order to program well in any Lisp you must be exposed to as many Lisps and as many other languages as possible.
If you think there’s a distinction between a ‘dialect’, a ‘jargon’ and a ‘language’ then I have news for you: there is. A language is a dialect with a standards committee. (This is stolen from a quote due to Max Weinrich that all linguists know:
אַ שפּראַך איז אַ דיאַלעקט מיט אַן אַרמיי און פֿלאָט
a shprakh iz a dyalekt mit an armey un flot.)
‘Language-in-a-string’ is where a programming language has another programming language embedded in strings in the outer language. Sometimes programs in that inner programming language will be made up by string concatenation in the outer language. Sometimes that inner language will, in turn, have languages embedded in its strings. It’s a terrible, terrible thing. ↩
via Erlang/OTP | News by Lukas Larsson on Tue, 02 Nov 2021 00:00:00 GMT
via Erlang/OTP | News by Kenneth Lundin on Tue, 26 Oct 2021 00:00:00 GMT
via Planet Lisp by on Fri, 22 Oct 2021 10:49:17 GMT
Recently, the awesome-lisp-companies list was posted on HN, more people got to know it (look, this list is fan-cooked and we add companies when we learn about one, often by chance, don’t assume it’s anything “official” or exhaustive), and Alex Nygren informed us that his company Kina Knowledge uses Common Lisp in production:
We use Common Lisp extensively in our document processing software core for classification, extraction and other aspects of our service delivery and technology stack.
He very kindly answered more questions.
We use SBCL for all our Common Lisp processes. It’s easier with the standardization on a single engine, but we also have gotten tied to it in some of our code base due to using the built in SBCL specific extensions. I would like, but have no bandwidth, to evaluate CCL as well, especially on the Windows platform, where SBCL is weakest. Since our clients use Windows systems attached to scanners, we need to be able to support it with a client runtime.
Development is on MacOS with Emacs or Ubuntu with Emacs for CL, and then JetBrains IDEs for Ruby and JS and Visual Studio for some interface code to SAP and such. We develop the Kina UI in Kina itself using our internal Lisp, which provides a similar experience to Emacs/SLY.
Presently we use a Rails/Ruby environment for driving our JSON based API, and some legacy web functions. However, increasingly, once the user is logged in, they are interacting with a Common Lisp back end via a web socket (Hunchentoot and Hunchensocket) interacting with a Lisp based front end. Depending on the type of information extraction, the system uses Javascript, Ruby and Common Lisp. Ideally, I’d like to get all the code refactored into a prefix notation, targeting Common Lisp or DLisp (what we call our internal Lisp that compiles into Javascript).
Yes. We recently put our JSON-LIB (https://github.com/KinaKnowledge/json-lib) out on Github, which is our internal JSON parser and encoder and we want to open source DLisp after some clean-up work. Architecturally, DLisp can run in the browser, or in sandboxed Deno containers on the server side, so we can reuse libraries easily. It’s not dependent on a server-side component though to run.
Library wise, we strictly try and limit how many third party (especially from the NPM ecosystem) libraries we are dependent on, especially in the Javascript world. In CL, we use the standard stuff like Alexandria, Hunchentoot, Bordeaux Threads, and things like zip.
Because we operate a lot in Latin America, I trained non-lisper engineers who speak Spanish on how to program Lisp, specifically our DLisp, since most customizations occur specifically for user interface and workflows around document centric processes, such as presenting linked documents and their data in specific ways. How the lisp way of thinking really depended on their aptitude with programming, and their English capabilities to understand me and the system. The user system is multilingual, but the development documentation is all in English. But it was really amazing when I saw folks who are experienced with Javascript and .Net get the ideas of Lisp and how compositional it can be as you build up towards a goal.
Besides, with DLisp, you can on the fly construct a totally new UI interaction - live - in minutes and see changes in the running app without the dreadful recompile-and-reload everything cycle that is typical. Instead, just recompile the function (analogous to C-c, C-c in Emacs), in the browser, and see the change. Then these guys would go out and interact with clients and build stuff. I knew once I saw Spanish functions and little DSLs showing up in organizational instances that they were able to make progress. I think it is a good way to introduce people to Lisp concepts without having to deal with the overhead of learning Emacs at the same time. I pushed myself through that experience when I first was learning CL, and now use Emacs every day for a TON of work tasks, but at the beginning it was tough, and I had to intentionally practice getting to the muscle memory that is required to be truly productive in a tool.
Right now, in our core company we have three people, two here in Virginia and one in Mexico City. We use partners that provide services such as scanning and client integration work. We are self-funded and have grown organically, which is freeing because we are not beholden to investor needs. We maintain maximum flexibility, at the expense of capital. Which is OK for us right now. Lisp allows us to scale dramatically and manage a large code base. I haven’t line counted recently, but it exceeds 100K lines across server and client, with > 50% in Lisp.
I really like the Common Lisp world. I would like it to be more popular, but at the same time, it is a differentiator for us. It is fast - our spatial classifier takes only milliseconds to come to a conclusion about a page (there is additional time prior to this step due to the OpenCV processing - but not too much) and identify it and doesn’t require expensive hardware. Most of our instances run on ARM-64, which at least at AWS, is 30% or so cheaper than x86-64. The s-expression structures align to document structures nicely and allow a nice representation that doesn’t lose fidelity to the original layouts and hierarchies. I am not as active as I would like to be in the Common Lisp community, mainly due to time and other commitments. I don’t know much about the CL foundation.
Our UI was first with the DLisp concepts. I was intrigued by Clojure for the server portion, but I couldn’t come to terms with the JVM and the heavyweight of it. The server-side application was outgrowing the Rails architecture in terms of what we wanted to do with it, and, at the time, 4 years ago, Ruby was slower. In fact, Ruby had become a processing bottleneck for us (though I am certain the code could have been improved too). I liked the idea of distributing binary applications as well, which we needed to do in some instances, and building a binary runtime of the software was a great draw, too.
I also liked how well CL is thought out, from a spec standpoint. It is stable both in terms of performance and change. I had been building components with TensorFlow and Python 3, but for what I wanted to do, I couldn’t see how I could get there with back propagation and the traditional “lets calculate the entire network state”. If you don’t have access to high end graphic cards, it’s just too slow and too heavy. I was able to get what we needed to do in CL after several iterations and dramatically improve speed and resource utilization. I am very happy with that outcome. We are in what I consider to be a hard problem space: we take analog representations of information, a lot of it being poor quality and convert it to clean, structured digital information. CL is the core of that for us.
Here is an example of our UI, where extractions and classification can be managed. This is described in DLisp which interacts with a Common Lisp back end via a web socket.
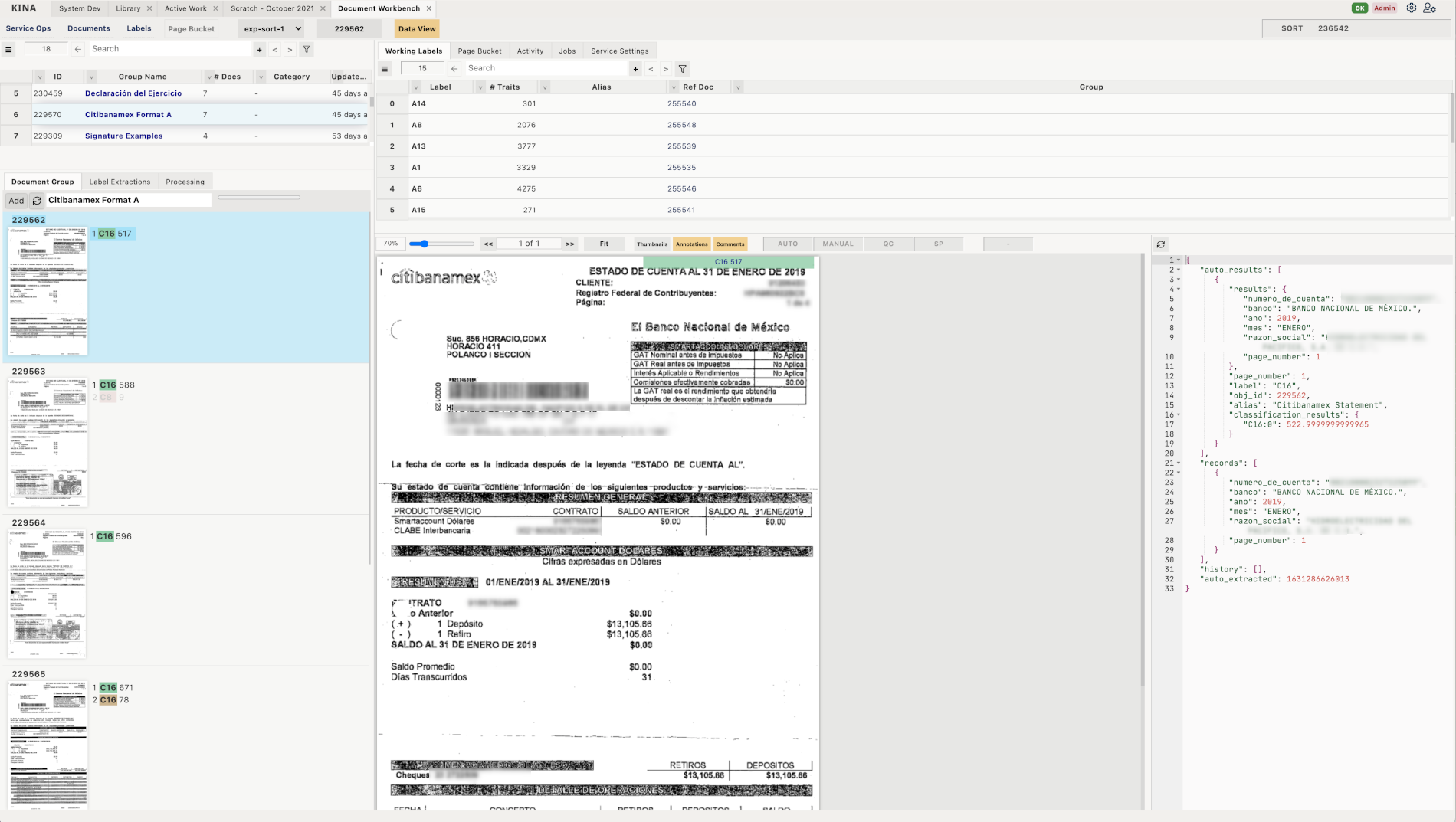
Here is the function for the above view being edited in Kina itself. We do not obfuscate our client code, and all code that runs on our clients’ computers is fully available to view and, with the right privileges, to modify and customize. You can see the Extract Instruction Language in the center pane, which takes ideas from the Logo language in terms of a cursor (aka the turtle) that can be moved around relative to the document. We build this software to be used by operations teams and having a description language that is understandable by non-programmers such as auditors and operations personnel, is very useful. You can redefine aspects of the view or running environment and the change can take effect on the fly. Beyond the Javascript boot scaffolding to get the system started up in the browser, everything is DLisp communicating with Common Lisp and, depending on the operation, Rails.

I hope this information is helpful!
It is, thanks again!
via Planet Lisp by on Thu, 21 Oct 2021 01:47:00 GMT
New projects:
Updated projects: 3d-matrices, also-alsa, april, architecture.builder-protocol, bdef, beast, bike, bnf, bp, chameleon, check-bnf, chirp, ci-utils, cl+ssl, cl-ana, cl-ansi-term, cl-ansi-text, cl-async, cl-bloggy, cl-collider, cl-colors2, cl-cron, cl-data-structures, cl-dbi, cl-digraph, cl-environments, cl-form-types, cl-forms, cl-gearman, cl-gserver, cl-info, cl-kraken, cl-liballegro-nuklear, cl-libsvm, cl-marshal, cl-megolm, cl-mixed, cl-opencl, cl-opencl-utils, cl-patterns, cl-pdf, cl-permutation, cl-png, cl-readline, cl-schedule, cl-sdl2-mixer, cl-ses4, cl-telebot, cl-utils, cl-wave-file-writer, cl-webdriver-client, cl-webkit, cletris, clj-re, clog, closer-mop, cluffer, clunit2, clx, cmd, colored, common-lisp-jupyter, concrete-syntax-tree, consfigurator, core-reader, croatoan, cytoscape-clj, dartsclhashtree, data-frame, defmain, dfio, djula, dns-client, doc, doplus, easy-routes, eclector, esrap, fare-scripts, fof, fresnel, functional-trees, gadgets, gendl, generic-cl, glacier, gtirb-capstone, gute, harmony, hash-table-ext, helambdap, hunchenissr, imago, ironclad, jingoh, kekule-clj, lack, lambda-fiddle, lass, legit, lisp-namespace, lisp-stat, literate-lisp, log4cl, log4cl-extras, lsx, maiden, markup, math, matrix-case, mcclim, messagebox, mgl-pax, micmac, millet, mito, mnas-graph, mnas-hash-table, mnas-package, mnas-string, mutility, null-package, numerical-utilities, nyxt, omglib, osicat, parachute, petalisp, physical-quantities, plot, portal, postmodern, pp-toml, prompt-for, qlot, query-repl, quilc, read-as-string, resignal-bind, rove, rpcq, salza2, sel, serapeum, sha1, shasht, shop3, sketch, slite, smart-buffer, spinneret, staple, static-dispatch, stealth-mixin, structure-ext, swank-protocol, sycamore, tfeb-lisp-hax, tfeb-lisp-tools, tooter, trace-db, trestrul, trivia, trivial-with-current-source-form, uax-15, uncursed, vellum, vellum-postmodern, vgplot, vk, whirlog, with-c-syntax, zippy.
Removed projects: adw-charting, cl-batis, cl-bunny, cl-dbi-connection-pool, cl-reddit, cl-server-manager, corona, gordon, hemlock, hunchenissr-routes, prepl, s-protobuf, submarine, torta, trivial-swank, weblocks-examples, weblocks-prototype-js, weblocks-tree-widget, weblocks-utils.
To get this update, use (ql:update-dist "quicklisp").
There are a lot of removed projects this month. These projects no longer build with recent SBCLs, and all bug reports have gone ignored for many months. If one of these projects is important to you, consider contributing to its maintenance and help it work again.
Incidentally, this is the eleventh anniversary of the first Quicklisp dist release back in October 2010.
via Lisp, the Universe and Everything by Vsevolod Dyomkin on Tue, 12 Oct 2021 10:50:00 GMT

Last week, I did a quick hack that quite delighted me: I added a way to visually watch the progress of training my MGL-based neural networks inside Emacs. And then people on twitter asked me to show the code. So, it will be here, but first I wanted to rant a bit about one of my pet peeves.
In the age of Jupyter and TensorBoard, adding a way to see an image that records the value of a loss function blinking on the screen — "huh, big deal" you would say. But I believe this example showcases a difference between low-tech and high-tech approaches. Just recently I chatted with one of my friends who is entering software engineering at a rather late age (30+), and we talked of how frontend development became even more complicated than backend one (while, arguably, the complexity of tasks solved on the frontend is significantly lower). And that discussion just confirmed to me that the tendency to overcomplicate things is always there, with our pop-culture industry, surely, following it. But I always tried to stay on the simple side, on the side of low-tech solutions. And that's, by the way, one of the reasons I chose to stick with Lisp: with it, you would hardly be forced into some nonsense framework hell, or playing catch-up with the constant changes of your environment, or following crazy "best practices". Lisp is low-tech just like the Unix command-line or vanilla Python or JS. Contrary to the high-tech Rust, Haskell or Java. Everything text-based is also low-tech: text-based data formats, text-based visualization, text-based interfaces.
So, what is low-tech, after all? I saw the term popularized by Kris De Decker from the Low-Tech Magazine, which focuses on using simple (perhaps, outdated by some standards) technologies for solving serious engineering problems. Most people, and the software industry is no exception, are after high-tech, right? Progress of technology enables solving more and more complex tasks. And, indeed, that happens. Sometimes, not always. Sometimes, the whole thing crumbles, but that's a different story. Yet, even when it happens, there's a catch, a negative side-effect: the barrier of entry rises. If 5 or 10 years ago it was enough to know HTML, CSS, and JavaScript to be a competent frontend developer, now you have to learn a dozen more things: convoluted frameworks, complicated deploy toolchains, etc., etc. Surely, sometimes it's inevitable, but it really delights me when you can avoid all the bloat and use simple tools to achieve the same result. OK, maybe not completely the same, maybe not a perfect one. But good enough. The venerable 80% solution that requires 20% effort.
Low-tech is not low-quality, it's low-barrier of entry.
And I would argue that, in the long run, better progress in our field will be made if we strive towards lowering the bar to more people in, than if we continue raising it (ensuring our "job security" this way). Which doesn't mean that the technologies should be primitive (like BASIC). On the contrary, the most ingenious solutions are also the simplest ones. So, I'm going to continue this argument in the future posts I'd like to write about interactive programming. And now, back to our hacks.
In my recent experiments I returned to MGL — an advanced, although pretty opinionated, machine learning library by the prolific Gabor Melis — for playing around with neural networks. Last time, a few years ago I stumbled when I tried to use it to reproduce a very advanced (by that time's standards) recurrent neural network and failed. Yet, before that, I was very happy using it (or rather, it's underlying MGL-MAT library) for running in Lisp (in production) some of the neural networks that were developed by my colleagues. I know it's usually the other way around: Lisp for prototyping, some high-tech monstrosity for production, but we managed to turn the tides for some time :D
So, this time, I decided to approach MGL step by step, starting from simple building blocks. First, I took on training a simple feed-forward net with a number of word inputs converted to vectors using word2vec-like approach.
This is the network I created. Jumping slightly ahead, I've experimented with several variations of the architecture, starting from a single hidden layer MLP, and this one worked the best so far. As you see, it has 2 hidden layers (l1/l1-l and l2/l2-l) and performs 2-class classification. It also uses dropout after each of the layers as a standard means of regularization in the training process.
(defun make-nlp-mlp (&key (n-hidden 100))
(mgl:build-fnn (:class 'nlp-mlp)
(in (->input :size *input-len*))
(l1-l (->activation in :size n-hidden))
(l1 (->relu l1-l))
(d1 (->dropout l1 :dropout 0.5))
(l2-l (->activation d1 :size (floor n-hidden 2)))
(l2 (->relu l2-l))
(d2 (->dropout l2 :dropout 0.5))
(out-l (->activation d2 :size 2))
(out (->softmax-xe-loss out-l))))
MGL model definition is somewhat different from the approach one might be used to with Keras or TF: you don't imperatively add layers to the network, but, instead, you define all the layers at once in a declarative fashion. A typical Lisp style it is. Yet, what still remains not totally clear to me yet, is the best way to assemble layers when the architecture is not a straightforward one-direction or recurrent, but combines several parts in nonstandard ways. That's where I stumbled previously. I plan to get to that over time, but if someone has good examples already, I'd be glad to take a look at those. Unfortunately, despite the proven high-quality of MGL, there's very little open-source code that uses it.
Now, to make a model train (and watch it), we have to pass it to mgl:minimize alongside with a learner:
(defun train-nlp-fnn (&key data (batch-size 100) (epochs 1000) (n-hidden 100)
(random-state *random-state*))
(let ((*random-state* random-state)
(*agg-loss* ())
(opt (make 'mgl:segmented-gd-optimizer
:termination (* epochs batch-size)
:segmenter (constantly
(make 'mgl:adam-optimizer
:n-instances-in-batch batch-size))))
(fnn (make-nlp-mlp :n-hidden n-hidden)))
(mgl:map-segments (lambda (layer)
(mgl:gaussian-random!
(mgl:nodes layer)
:stddev (/ 2 (reduce '+ (mgl:mat-dimensions (mgl:nodes layer))))))
fnn)
(mgl:monitor-optimization-periodically
opt
`((:fn mgl:reset-optimization-monitors :period ,batch-size :last-eval 0)
(:fn draw-test-error :period ,batch-size)))
(mgl:minimize opt (make 'mgl:bp-learner
:bpn fnn
:monitors (mgl:make-cost-monitors
fnn :attributes `(:event "train")))
:dataset (sample-data data (* epochs batch-size)))
fnn))
This code is rather complex, so let me try to explain each part.
(let ((*random-state* random-state) to ensure that we can reproduce training in exactly the same way if needed. mgl:segmented-gd-optimizer is a class that allows us to specify a different optimization algorithm for each segment (layer) of the network. Here we use the same standard mgl:adam-optimizer with vanilla parameters for each segment (constantly). mgl:map-segments call is performing the Xavier initialization of the input layers. It is crucial to properly initialize the layers of the network before training or, at least, ensure that they are not all set to zeroes. mgl:monitor-optimization-periodically is a hook to make MGL invoke some callbacks that will help you peek into the optimization process (and, perhaps, do other needful things). That's where we insert our draw-test-error function that will run each batch. There's also an out-of-the-box cost-monitor attached directly to the mgl:bp-learner, which is collecting the data for us and also printing it on the screen. I guess, we could build the draw-test-error monitor in a similar way, but I opted for my favorite Lisp magic wand — a special variable *agg-loss*.
(sample-adata data (* epochs batch-size)). The simple approach that I use here is to pre-sample the necessary number of examples beforehand. However, streaming sampling may be also possible with a different dataset-generating function. Now, let's take a look at the function that is drawing the graph:
(defun draw-test-error (opt learner)
;; here, we print out the architecture and parameters of
;; our model and learning algorithm
(when (zerop (mgl:n-instances opt))
(describe opt)
(describe (mgl:bpn learner)))
;; here, we rely on the fact that there's
;; just a single cost monitor defined
(let ((mon (first (mgl:monitors learner))))
;; using some of RUTILS syntax sugar here to make the code terser
(push (pair (+ (? mon 'counter 'denominator)
(if-it (first *agg-loss*)
(lt it)
0))
(? mon 'counter 'numerator))
*agg-loss*)
(redraw-loss-graph)))
(defun redraw-loss-graph (&key (file "/tmp/loss.png") (smoothing 10))
(adw-charting:with-chart (:line 800 600)
(adw-charting:add-series "Loss" *agg-loss*)
(adw-charting:add-series
(fmt "Smoothed^~a Loss" smoothing)
(loop :for i :from 0
:for off := (* smoothing (1+ i))
:while (< off (length *agg-loss*))
:collect (pair (? *agg-loss* (- off (floor smoothing 2)) 0)
(/ (reduce ^(+ % (rt %%))
(subseq *agg-loss* (- off smoothing) off)
:initial-value 0)
smoothing))))
(adw-charting:set-axis :y "Loss" :draw-gridlines-p t)
(adw-charting:set-axis :x "Iteration #")
(adw-charting:save-file file)))
Using this approach, I could also draw the change of the validation loss on the same graph. And I'll do that in the next version.
ADW-CHARTING is my goto-library when I need to draw a quick-and-dirty chart. As you see, it is very straightforward to use and doesn't require a lot of explanation. I've looked into a couple other charting libraries and liked their demo screenshots (probably, more than the style of ADW-CHARTING), but there were some blockers that prevented me from switching to them. Maybe, next time, I'll have more inclination.
To complete the picture we now need to display our learning progress not just with text running in the console (produced by the standard cost-monitor), but also by updating the graph. This is where Emacs' nature of a swiss-army knife for any interactive workflow came into play. Surely, there was already an existing auto-revert-mode that updates the contents of a Emacs buffer on any change or periodically. For my purposes, I've added this lines to my Emacs config:
(setq auto-revert-use-notify nil)
(setq auto-revert-interval 6) ; refresh every seconds
Obviously, this can be abstracted away into a function which could be invoked by pressing some key or upon other conditions occurring.
A nice lisp/interactive dev hack I did today: watching an MGL neural net train with a chart dynamically redrawn by adw-charting and updated inside Emacs by auto-revert-mode. Slime/Emacs - the ultimately customizable interactive experience FTW pic.twitter.com/y5ie9Xm20D
— Vsevolod (@vseloved) October 6, 2021
via Erlang/OTP | News by Kenneth Lundin on Tue, 21 Sep 2021 00:00:00 GMT
via Erlang/OTP | News by Henrik Nord on Wed, 12 May 2021 00:00:00 GMT
via Erlang/OTP | News by Henrik Nord on Tue, 20 Apr 2021 00:00:00 GMT
via Erlang/OTP | News by Henrik Nord on Fri, 26 Mar 2021 00:00:00 GMT
via Erlang/OTP | News by Henrik Nord on Wed, 24 Mar 2021 00:00:00 GMT